



貸出履歴の活用は、いつも話題にはなるものの、図書館界では、どこかタブーの感があります。それでも、実際に貸出履歴を活用したシステムが既に公開されているのも現状です。
11月7日にパシフィコ横浜で開催されたフォーラムでは、私が前座を務め、法学者とEC(電子取引)の検索エンジン開発者から専門的なお話をいただきました。今日はフォーラムの内容を紹介します。
まず、私から、現状の貸出履歴の活用事例と課題や問題点を整理させていただきました。貸出履歴をシステムで利用したい要望には2つの視点があります。
一つは利用者からの要望です。自分が以前何を借りたのか知りたいのです。カウンターでは、お年寄りに多い要望と聞いています。最近は、通帳のように読書記録を記録する“読書手帳システム”を導入する図書館も増えてきました。“My本棚”は、借りた本や気になる本を、Web上で、あたかも自分の本棚に置くような機能です。アマゾンのお奨めリストのような“レコメンドサービス”を提供するシステムもあります。
もう一つは、図書館からの要望です。以前から多いのは汚破損対策です。貸出中の本の場合は、当然借りている利用者とリンクをしていますが、返却された本についても、前に誰が借りたか紐解ける仕組みになっているシステムもあるようです。
そして、更なる貸出履歴の活用として、今注目しているのが、“ビッグデータ”の活用です。
同じような言葉でオープンデータというのがあります。オープンデータは、国や自治体などの公益事業者等が保有する公共データをビジネスなどに活用できるよう提供するデータのことです。一方、ビッグデータとは、単に量が多いだけでなく、様々な種類・形式が含まれる日々膨大に生成・記録され今までは管理しきれなかったデータ群を記録・保管して解析することで、ビジネスなどの新しい活用路を見出すデータをいいます。(注1)
貸出履歴を活用するうえで、以下の問題点や課題をあげました。
法律の専門家である湯淺氏から、幾つかの観点から法的問題を解説していただきました。
貸出履歴に関わる法制度には、憲法の思想・信条の自由をはじめ、図書館法、地方公務員法の守秘義務、地方自治法の指定管理者制度、各地方公共団体の関連条例などがあります。
まず、「そもそも貸出履歴データを利用する権利は誰にあるのか?」と、投げかけられました。「個人情報」に該当する場合は、本人の開示請求があれば見ることができるのだそうです。Tポイントなどは第三者にデータを提供していますが、共同利用という仕組みをとっており、例えば会社ごとどこかへ売った場合は、事業継承として引き継がれます。従って、図書館の場合、収集や利用に制限がかかってはいるものの、情報主体である本人からの開示請求があれば、貸出履歴を本人に開示することができるということでした。また、個人情報保護条例そのものが自治体によって違い、個人情報の定義が、「生存する」とか、「他の情報と容易に照合」など細かい条件の有無によって内容に大きく影響します。
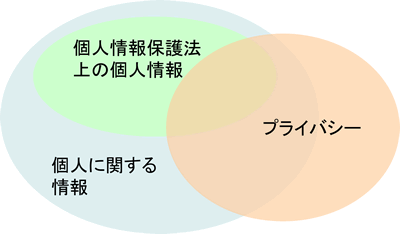
では、匿名化すれば「個人情報」に当たらなくて、自由に利用可能で、プライバシーに関する問題は生じないかといえば違います。個人を「特定」することと、「識別」することは同じではなく、「容易」の照合基準も、きわめてグレー。個人に関する情報の中で、個人情報保護法の個人情報とプライバシーとの関係も、ベン図で示すと、ねじれた構造になっています。プライバシーは憲法上の権利で、個人情報保護法の個人とは同じではありません。プライバシーをある種の財産としてお金に換えたのがTポイントカードと言われ、思わずそこだけは納得できました。
民間事業者が公立図書館の指定管理者になった場合の法的問題も触れていただきました。
公立図書館の場合、独立行政法人・国の行政機関・地方公共団体・民間事業者の個人情報保護法の規制がかかります。民間事業者が、複数の公立図書館の指定管理者になっている場合、個人情報保護条例は自治体ごとに違うため、本来は別々に取り扱わなければいけません。また指定管理者が仕様書を作成する場合、自社に優位な仕様書を作成するリスクも起こりえます。
色々お話を聴いていて、聴けば聴くほどグレーな部分が多くて、ますますタブー領域の感が強くなりました。法律の改正を待って、社会のニーズを見極めながら適応していくしかなさそうです。
井上氏は、Web上での商品取引(EC)の検索エンジンのスペシャリストです。
開発した検索エンジンが、どんな仕組みで動いているか興味深いお話でした。
そもそもECの検索は図書館の検索とは違います。図書館の検索はアイウエオ順のような「ソーティング」ですが、ECでは独自の「ランキング(順位付け)」を重要視します。お客様が欲しい良い検索とは、新鮮で、相関性が高く、売れ筋が反映されているものが表示されることです。
そのために、お客様の行動を学習して生かす「KAIZENを回す」と表現されていた以下の処理をひたすら繰り返しているとのこと。
即ち、ログを見る→仮説を立てる→アルゴリズムを改善する→テストする→ログを見る・・・・・・
検索エンジンだから、全てがプログラムで自動的におこなわれていると思ったら大間違い。
「良いサービス」のためには、人の運用が山ほどあります。商品データの登録、商品画像、カテゴリ構造、中間テーブル、同義語、形態素解析辞書登録など切りのない入力と日々の管理が支えています。
例えば、私たちがクリックして直ぐに戻ったのか、数秒迷って戻ったのか、カートに入れて迷って戻ったのか、こういう情報も全てウェイト付けして解析しているのだそうです。リアルなデータを1日1回はチェックし、最低1週間から3か月ほどは追跡して解析しているとのことでした。EC検索は、データ量がシグナルの強さに比例します。アマゾンが優れているのは、データ量が多いからで、他に匹敵するところはないとのことでした。
驚いたのは、サービスを解析するのに個人情報は利用しません。Web上ではクッキーから、どういう軌跡を辿ってどうたどり着いたかが重要との考えは、今までの図書館の検索ではあまり意識していなかったところです。
ビッグデータは最低でも100万人以上のデータが必要との話もありました。
最後に、図書館で活用できるデータは何かとの話になり、「そもそも図書館システムのゴールは何か?」と逆に問いかけられました。ショッピングサイトには明白な“売上”というゴールがあります。「図書館のゴールが決まらなければデータ活用がぶれる」とも。
活用できるデータは、貸出履歴や予約のほかに、今まで注目してこなかった閲覧履歴、やWebサイトのログ(クリック、お気に入り、レビュアー、シェア)・・・etc
ある程度の規模がないとビッグデータにはなりませんが、その規模をどうやって確保して読者の利便性へとつなげるか。直接の回答はありませんでしたが、ヒントはいただきました。
まずは、「図書館のゴールはどこですか?」の問いに、答えを導くことから始めてみましょう。
SEと一言でいっても、開発・導入・保守と様々なSEがいます。在職中、私たちのチームは、全員が導入も保守も携わっていましたが、それでも業務のウェイトは人によって違っていました。
主に保守を担当していたSEに、「何が一番の想い出?」と聞いたら、この話が返ってきました。
図書館でインターネット公開がまだ珍しい15年近く前の話で、地方の小さな図書館でインターネット検索をリリースした翌日のことです。早朝、K館長から「昨日は気づかへんかったけど、インターネットの使い方ボタンをクリックすると、他の図書館が表示されるんですわ!」。そんなバカな!と電話を片手にその図書館のホームページで試してみると、確かに他の図書館へいきなりワープしてしまいました。あまりの離れ業に、耳元の館長の存在も忘れ、思わず吹き出してしまいました。
「まあ、それでもいいんですが・・・。。」と館長。「いえいえ、とんでもありません。直ぐになおさせます」と私。SEに連絡したら、彼から出た言葉は、「あっ!!」。サンプルにお見せした設定ファイルの一か所を修正し忘れていたのです。一般の方が目にする前に修正できたものの、館長の人柄に救われた事件でした。一番の想い出と話してくれたSEは、今なら始末書ものの失態を、怒ることもなく穏やかに「ありがとう」と言ってくれた館長の優しい言葉が、今でも忘れられないそうです。
現在の品質体制ではこのようなミスはありえませんが、当時としても決して許される失敗ではありません。それでも対応に対してお礼を言われると、SEも救われた想いになります。何だか書いていて、小さな子供がお母さんから叱られている気持ちになりました。
図書館つれづれ

執筆者:ライブラリーコーディネーター
高野 一枝(たかの かずえ)氏